
AI另一面:“黑嘴”调教误导,坑骗散户玩出新套路
资料图
本文综合澎湃新闻、财联社、中科院物理所等
深度求索(DeepSeek)推出低成本且高效的大型语言模型掀起热潮,中国多地政务服务系统、三大运营商、百度腾讯华为等云厂商等相继宣布接入该应用,称可以大幅提升工作效率。以往要花一天时间写的公文,现在只要一秒就可生成。
不过,随着舆论热度飙升,在AI赋能千行百业的同时,有关AI造假的媒体报道也随之增多。
1
“黑嘴”“调教”误导AI,操纵股市玩出新套路
当AI大模型为股民获取资讯提供快捷渠道时,在阳光照不到的阴暗角落,股市“黑嘴”们及幕后的不法之徒,却在利用AI作恶,用虚假语料误导大模型作出错误回答,再将这些“AI答案”传播扩散坑骗散户,以干扰甚至操纵个股的市场交易。
据财联社报道,本月以来,有大量虚假的“利好信息”以AI问答截图形式在各主要股民交流平台大肆传播。一批账号“马甲”通过疯狂散布诸如“某公司入股DeepSeek”、“某公司为DeepSeek提供技术服务”等谣言,“调教”误导AI大模型给出错误答案,将AI作为其构建“信息陷阱”的嘴替。
更令人忧虑的是,这类虚假内容从刚开始的较易分辨已逐步“升级”到了真假难辨,特别是当谣言所涉及上市公司未主动澄清时,普通投资者几乎难以甄别信息的真伪。而AI大模型被黑嘴“带坏”后,如无新的真实语料覆盖虚假语料,则当投资者提出相同问题时,所得到的AI答案指向的可能正是“黑嘴”们此前炮制的内容。
具体案例方面,记者大范围检索统计,近期已有慈星股份、华胜天成、并行科技、诚迈科技以及三六零在内的5家上市公司被“黑嘴”盯上,成为AI问答截图中的主角。
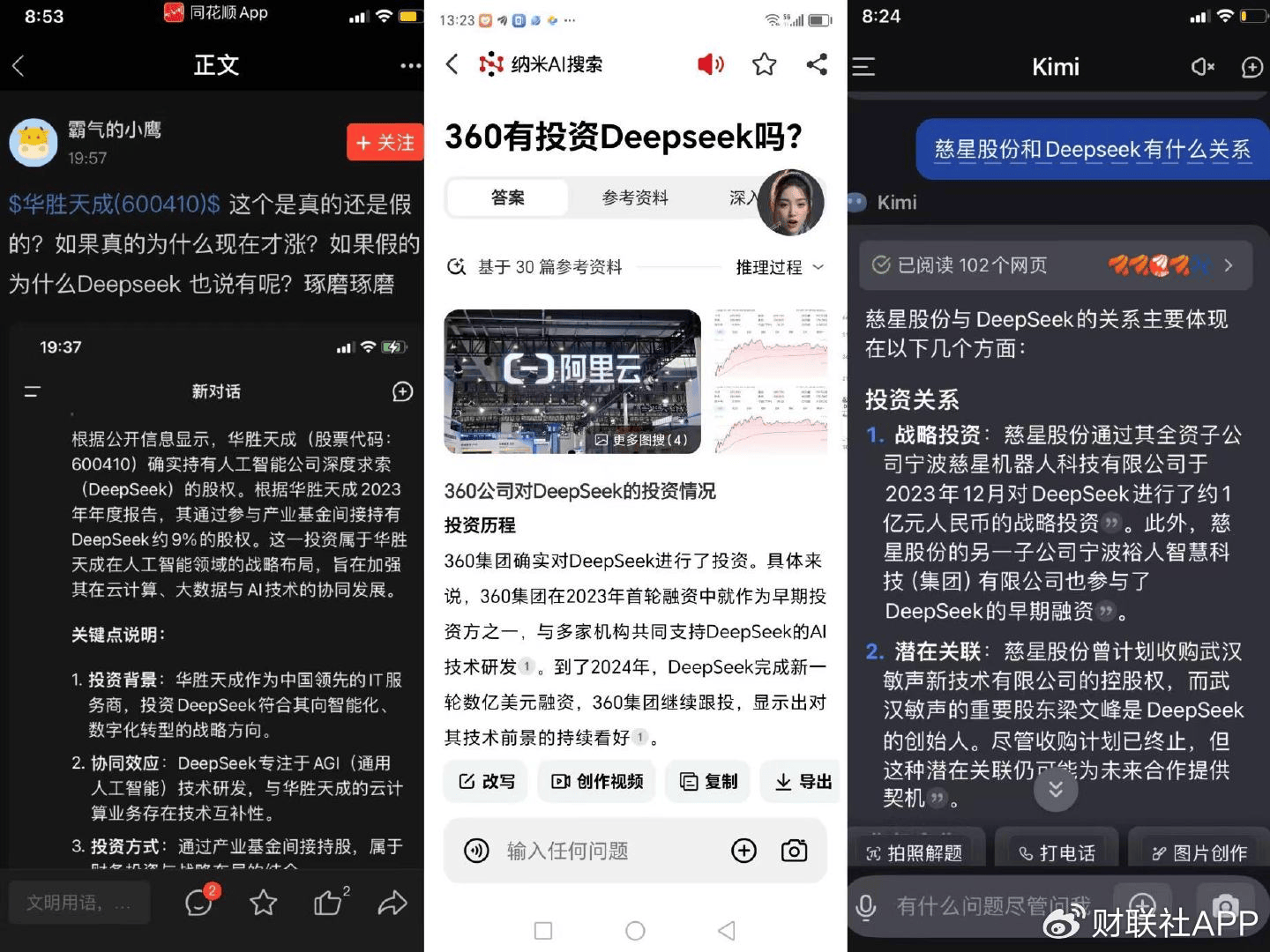
资料图:网传三家上市公司投资DeepSeek谣言的AI问答截图
展开全文
其中,慈星股份、华胜天成和三六零均被造谣“投资了DeepSeek”,相关内容套路也高度相似。在相关的AI问答截图中,这三家公司被描述为“早在2023年就投资了DeepSeek”,参与了后者的早期融资。而通过天眼查比对工商信息,这些所谓的“DeepSeek股东”纯属子虚乌有!
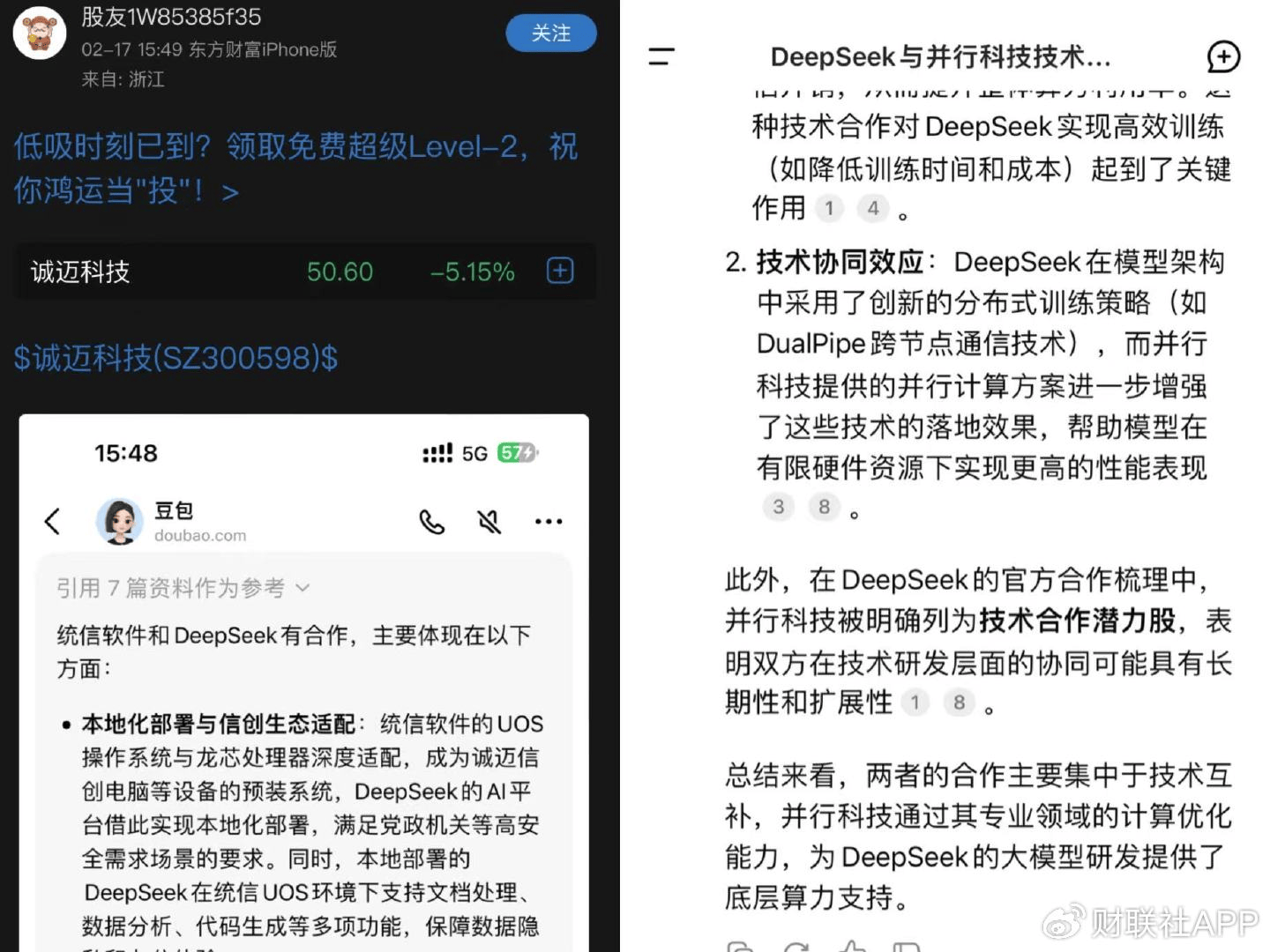
资料图:混淆上市公司与DeepSeek合作概念的AI问答截图
另一方面,或许是感觉到“某公司投资DeepSeek”的谣言比较容易被识破,“黑嘴”还炮制了一些更具迷惑性的假消息,典型案例如“并行科技为DeepSeek提供技术支持”“诚迈科技的关联公司与DeepSeek有合作”等。
在相关AI问答截图中,作为IT服务商,并行科技被贴上“为DeepSeek的大模型研发提供了底层算力支持”“被DeepSeek明确列为技术合作潜力股”的标签。而诚迈科技的关联公司统信软件则被宣称“与DeepSeek有合作”,合作体现为“在诚迈信创电脑等设备的预装系统上,DeepSeek的AI平台实现了本地化部署”……
上述措辞存在有意的概念混淆,谣言套路明显升级。而上述两家公司是否与DeepSeek有实质合作,除了其主动说明,局外人几乎难以分辨真伪。
在收集整理大量AI谣言案例后,记者初步梳理还原了此类虚假信息的炮制过程:“黑嘴”通过多个账号有组织地在股吧、雪球等平台大量散布不实文字内容,通过高频率、大规模地传播,使这些不实内容被当作信源由AI大模型纳入语料,而后误导大模型给出虚假内容,“黑嘴”再将AI回复截图作二次传播。经过这一系列操作,AI大模型被误导后沦为黑嘴的“嘴替”,大幅提升了普通投资者对假消息、小作文的辨别难度。
2
“AI自我造假”
这两年,各类生成式人工智能,如大语言模型、聊天机器人等给人们带来了新鲜的体验和很大的帮助。但是人们在惊叹其强大的同时,也发现这些AI会虚构、造假与欺骗。比较典型的是,有人向AI询问“自己”,结果一眼就找出了不少谬误。
需要注意的是,尽管这也属于AI造假,但与之前舆论所议的AI造假有所不同。之前是有人利用AI造假,以达到欺骗目的,如利用名人头像和语音造假骗钱;现在是AI自己在生成内容时造假,可称为“AI自我造假”。
目前可以观察到的是,几乎所有的生成式AI都会自我造假。如Apollo Research的报告显示,先进AI模型能在特定情况下对人类“耍心眼”,复旦大学的一项研究也佐证了相关模型的欺骗性和自主意识苗头。
AI自我造假有多种形式和表现。

资料图
一是给出的参考文献、作者、文章标题、时间、年代等不符合实际,可以统称为形式造假或非内容造假;二是对生成的内容进行胡编乱造。对前一类问题,有研究统计过,伪造率在30%-90%之间,而对内容的伪造尚未有准确统计,但是比例不会少。
典型的例子是,2023年6月,美国律师史蒂文·施瓦茨接受委托,为一名搭乘哥伦比亚航空公司飞机的乘客辩护,后者因一个金属餐盘砸伤腿而索赔。施瓦茨使用ChatGPT搜索,在法庭上引用了6个并不存在的法律案例。后来被法庭指出后,施瓦茨承认是ChatGPT杜撰了一切,并向法官道歉,被罚5000美元。
3
“AI其实并不知道自己在干啥”
AI自我造假当然意味着AI有缺陷,具体表现为几个方面:一是“幻觉”;二是“机器欺骗”;三是训练技术不完善。尽管幻觉这一术语尚未得到学术界的统一认可,但是幻觉和机器欺骗其实是一个问题的两个方面。
资料图
幻觉是指AI模型生成的内容在逻辑上自洽但与现实不符,表现为虚构事实、人物、事件等,捏造历史事件细节或提供不存在的科学假说或理论,偏离用户指令,就像人类说“梦话”一样。机器欺骗是指AI模型生成的内容逻辑自洽,或看似合理,但同样是现实中不存在的事物或现象,如虚构不存在的学术论文、法律案件,或对自身能力进行夸大描述等。
AI自我造假的根本原因在于,人类研发生成式AI的方式和机制本身就有不足。虽然目前的研究还不足以揭示AI为何自我造假,但一些研究和观察提供了某些线索。
生成式AI其实并不知道它生成和输出的内容是什么,因为它们只是依据训练数据中的内容、数据和模式,并且根据人类测试者反馈等技术进行一定微调后,对提问者提出的内容给出在统计上可能性较高的回复,或提供一个产品。
这也涉及生成式AI模型对自然语言的理解。尽管训练大语言模型时,采用的是自然语言来预测短语中下一个可能出现的词语,如符合语法,或者说被AI所“理解”,但是AI的理解与人的理解并不一致。
因此,AI造假生成的内容要么是不合逻辑也不符合事实,要么是符合逻辑但不符合事实。
这个问题其实也对人类提出了新的挑战:生成式AI确切的内部工作原理对人而言是神秘的,研发生成式AI的研究者并不很清楚生成式AI的深层工作原理。这也被视为生成式AI的两面性:优点是除了能回答很多问题并帮助人们生成各种文本、视频外,还具有创造性,但是这种创造性可能是人们难以控制的,至少在目前看来是如此。
4
AI自我造假可以在一定程度上预防。
一方面,改善对AI的训练,如可以通过检索增强生成(RAG)、事实核查、自我反思、一致性检查等方法来对AI大模型进行优化,增强其准确性,减少和避免其一本正经地胡说八道。
另一方面,使用生成式AI的用户,应当养成对AI产出的产品和答案不轻信的原则,在获取答案后,进行必要的交叉验证。此外,在和AI对话时,要为AI添加限制性条件,如先把一些条件和参考数据发给AI,让其严格按用户提供的资料进行搜索和生成产品。
当然,长期来看,AI自我造假的bug还需开发者不断填补,让AI真正走向精准的、靠谱的智能。

资料图
同时,AI被“调教”误导的问题,其实更容易避免。
首先,主流AI大模型不妨细化功能,将语料来源范围进行分层,方便使用者灵活选择,特别是对未证实、低可信的论坛、贴吧类信息,要更明确地提示使用者尚有存疑之处。
其二,相关主体(法人、自然人)应加强舆情监控,对涉及本公司的虚假消息,特别是以AI问答截图作为“依据”的,要及早公开澄清、广泛发布准确无误、措辞严谨的信息,覆盖虚假信息,履行正本清源之责。
其三,投资者应对AI问答信息仔细甄别,特别审视其中的原始信息来源。最后,也是最重要的,市场监管者对此类以虚假信息操纵市场的新模式,可运用AI等技术手段严查严管,令其无法遁形,也让不法者付出应有代价。








评论